Website Vulnerability Scanner
Overview
The Website Vulnerability Scanner systematically analyzes and evaluates the security posture of a web application. It uses a range of techniques, including automated vulnerability scanning and code analysis, to identify potential weaknesses, vulnerabilities, or misconfigurations that attackers could exploit.
The Website Vulnerability Scanner interacts with the target web application by crawling its pages, submitting forms, and simulating user interactions. The tool examines various components, such as web pages, URLs, forms, server configurations, and underlying code, to detect security flaws.
It excels in its ability to reduce the number of false positives, which has been its primary focus since its creation. As such, the scanner automatically validates certain findings by leveraging the identified vulnerabilities, distinguishing them in reports with the "Confirmed" tag.
Designed and developed by our dedicated team of 9 engineers, the Website Vulnerability Scanner on Pentest-Tools.com is a custom tool, which uses a combination of predefined security tests and patterns, along with heuristic analysis and pattern recognition, to identify common vulnerabilities like SQL injection, cross-site scripting (XSS), insecure file uploads, and more. It leverages the most respected security standards and frameworks to cross-reference findings and assess their severity.
The Pentest-Tools Website Vulnerability Scanner combines all those features into one comprehensive tool, actively and passively performing tests, offering the option to conduct authenticated scans, and allowing customization of various scan options.
This custom tool is a full-blown web application scanner, capable of performing comprehensive security assessments against any type of web application - from simple one-page sites to complex modern sites that rely heavily on Javascript.
Usage
Security professionals use the Website Vulnerability Scanner to run web application security scans to identify known vulnerabilities and misconfigurations in server software, JavaScript libraries, SSL/TLS certifications, client access policies, and other elements.
→ Pentest web apps
Accelerate your pentest using this online website security checker. Choose from pre-configured, optimal settings for the best results and performance. Simply initiate the scan and receive a notification when the results are ready.
→ Authenticated web security scans
To consider a comprehensive security evaluation of a web app complete, it is essential to actively conduct authenticated scans. Our Website Vulnerability Scanner caters to any type of authentication utilized by your target. Supported authentication methods include:
→ Detect sensitive data exposure
Perform a comprehensive examination to identify vulnerabilities and misconfigurations that expose sensitive data within web apps - such as email addresses, social security numbers, credit card numbers, and more. Uncover issues that impact both data in transit and data at rest, including problems related to SSL/TLS, unprotected data backups, configuration files, and other potential areas of concern.
→ Map the attack surface automatically
Automate mapping the attack surface by visualizing and filtering the web technologies your target uses to identify indicators of exposure and high-risk areas (such as outdated server software, vulnerable technology versions, and more). Our online Website Vulnerability Scanner seamlessly integrates its findings, including screenshots, into the Attack Surface view, alongside other tools available on the platform.
→ Security self-assessment
Actively perform self-assessments of your own website to identify security vulnerabilities present in your web application. Obtain clear and easy-to-follow recommendations from each site vulnerability check and utilize them to proactively address web security issues before they can be exploited by potential attackers.
→ Audit third-party websites
As a web development company, you can use the security report to demonstrate to your clients that you have implemented appropriate measures to ensure the safety and functionality of their web applications.
Architecture
Here’s the breakdown of the Website Scanner’s architecture and the successive steps it takes to help you understand how it works and how to use it to its full potential. See the full image »
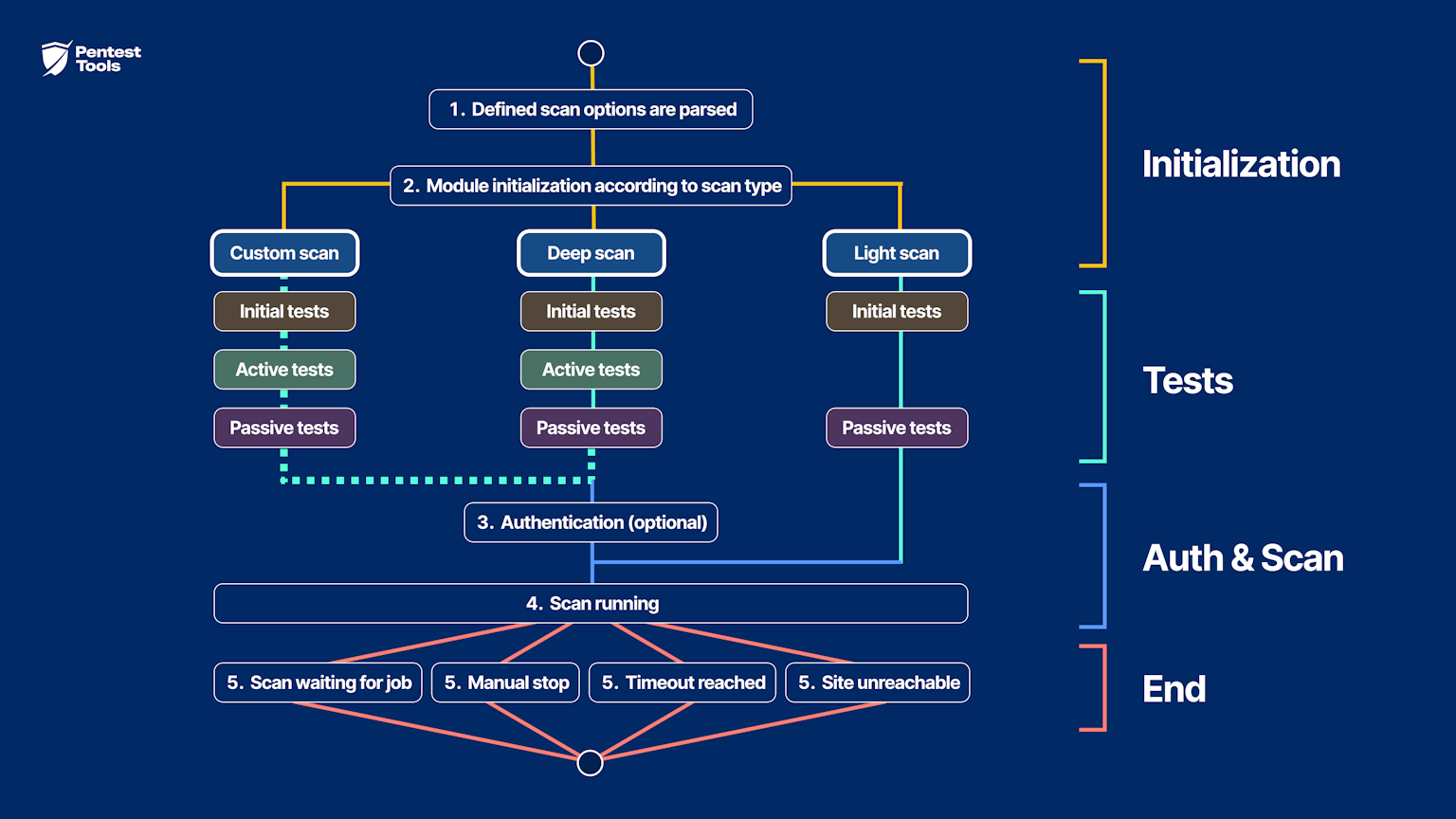
The scanning engine parses the scan options.
The scanners initialize with their specific options:
↳ Spidering - a map of the website is built (runs for all scan types, but is limited in time for the Light Scan)
↳ Initial tests run
↳ Active tests run - vulnerabilities all of the endpoints that the Spider discovered are scanned (is run for Deep and, if selected, for Custom Scan types)
↳ Passive tests run - vulnerabilities in the HTTP responses that the server sent for the requests made by Spidering and the Active Scanner are identified
Authentication on the website (optional, for Deep and Custom Scan types)
The scanners are started
Scanners will run until one of the following stopping conditions are met:
all the scanners are waiting for jobs
the user requested the scan to stop
the scan timeout period (default: 24 hours) is reached
the website becomes unreachable
Scan types
There are two predefined scan types (Light and Deep), as well as a Custom option that allows you to define the various scanner parameters such as the initial tests that the scanner will perform, various scan engine options as well as the attack options at a granular level.
Light Scan
The Light Scan option offers a quick overview of the website and provides a report highlighting the identified website technologies and associated vulnerabilities usually under a minute. It serves as a quick assessment to provide initial insights into the website's potential security issues and technology stack.
Light tests performed
This is the list of the tests performed by the Light Scan. For more details on each of them, please see the Tests performed section.
☑ Fingerprint web server software
☑ Analyze HTTP headers for security misconfiguration
☑ Check the security of HTTP cookies
☑ Check the SSL certificate of the server
☑ Check if the server software is affected by known vulnerabilities
☑ Analyze robots.txt for interesting URLs
☑ Check whether a client access file exists, and if it contains a wildcard entry (clientaccesspolicy.xml, crossdomain.xml)
☑ Discover server configuration problems such as Directory Listing
☑ Check if HTTP TRACK/TRACE methods are enabled
☑ Check if security.txt is missing on the server
Available configuration
Note: despite its notable speed, this detection method is susceptible to generating false positives due to its sole reliance on the reported service versions, which are subject to potential inaccuracies.
Deep Scan
This is the default selection when initiating a scan. It is a comprehensive scan type with a maximum runtime of 24 hours and is specifically designed to detect vulnerabilities outlined in the OWASP Top 10 list.
By default, all available test options are enabled for the Deep Scan.
While it is generally recommended to retain the default settings, there may be certain instances where customization is necessary. For instance, if you are dealing with an exceptionally large application or need to exclude specific sections from the scan, you can configure these settings accordingly using the Custom Scan feature. Further details on customizing the scan settings are provided in the subsequent section.
Deep tests performed
This is the list of the tests performed by the Deep Scan. For more details on each of them, please see the Tests performed section.
☑ Fingerprint web server software
☑ Analyze HTTP headers for security misconfiguration
☑ Check the security of HTTP cookies
☑ Check the SSL certificate of the server
☑ Check if the server software is affected by known vulnerabilities
☑ Analyze robots.txt for interesting URLs
☑ Check whether a client access file exists, and if it contains a wildcard entry (clientaccesspolicy.xml, crossdomain.xml)
☑ Resource discovery
☑ Discover server configuration problems such as Directory Listing
☑ Check if HTTP TRACK/TRACE methods are enabled
☑ Check if “security.txt” is missing on the server
☑ Check if CORS is misconfigured
☑ Crawl website
☑ Check for SQL Injection
☑ Check for Cross-Site Scripting
☑ Check for Local File Inclusion and Remote File Inclusion
☑ Check for OS Command Injection
☑ Check for ASP Cookieless Cross-Site Scripting
☑ Check for Server Side Request Forgery
☑ Check for Open Redirect
☑ Check for Broken Authentication
☑ Check for PHP Code Injection
☑ Check for JavaScript Code Injection
☑ Check for Ruby Code Injection
☑ Check for Python Code Injection
☑ Check for Perl Code Injection
☑ Check for Log4j Remote Code Execution
☑ Check for Server-Side Template Injection
☑ Check for ViewState Remote Code Execution
☑ Check for Client-Side Prototype Pollution
☑ Check for Exposed Backup Files
☑ Check for Request URL Override
☑ Check for Client-Side Template Injection
☑ Check for HTTP/1.1 Request Smuggling
☑ Check for outdated JavaScript libraries
☑ Find administrative pages
☑ Check for sensitive files (archives, backups, certificates, key stores) based on hostname and some common words
☑ Attempt to find interesting files/functionality
☑ Check for information disclosure issues
☑ Weak Password Submission Method
☑ Clear Text Submission of Credentials
☑ Verify Domain Sources
☑ Check for commented code/debug messages
☑ Find Login Interfaces
☑ Sensitive Data Crawl
Engine Options
Spidering approach: the Deep Scan will automatically determine which of the two options to use - “Classic” (to crawl classic, static websites) or “Single-page Application”.
Scan limits - Maximum Spidering depth: 10, Maximum requests per second: 100.
Available configuration
Note: The Deep Scan generates a high amount of noise in the network. Most correctly configured IDSs will detect this scan as attack traffic. Do not use it if you don't have proper authorization from the target website owner.
Custom Scan
This scan type allows you to define all parameters individually, from the list of tests you want to run, to the spidering level or certain URLs you want to omit from the scan.
Initial tests performed
The list of initial tests performed by the Custom Scan is entirely configurable by toggle switches. Please see the full list of tests and their description in the Initial tests section below.
Engine Options
The Custom Scan type allows you to set specific options regarding the desired depth of the application crawl or define specific paths that you want the scanner to exclude.
Spidering approach
Set the spidering (the process that goes through the website, following every link and looking for the next page it needs to visit) method to use during the scan.
Info: Spidering can be likened to Fuzzing, where the directories and files resident on the website are discovered and logged for later active vulnerability scanning. We also have a dedicated tool for that - the URL Fuzzer.
There are two options to choose from, according to the type of website you want to scan:
Classic - use this option to crawl classic, static websites. It is generally faster but does not work well for modern, Javascript-heavy websites.
Single-page Application (SPA) - crawl single-page application (JavaScript-heavy) websites. This method is slower than Classic spidering.
Limits
Adjust the spidering depth and number of requests that can be made per second.
Spidering Depth - set the number of subpaths (number of ‘/’ in the URL) the spidering will reach. Keep in mind that while a higher depth number will allow you to discover more injection points, it will also increase the scan process duration. We recommend keeping the default value of:
10.Requests per second - set the number of maximum requests per second that the scanner is allowed to make (the actual request number may be lower). Defaults to: 100.
Included and excluded URLs
Allows you to define specific URLs to be included or excluded from the scan. Enter them manually, one per line.
Included URLs - add URLs that are harder to find automatically, are not linked to other endpoints or go beyond the Spidering Depth limit.
Excluded URLs - useful for defining endpoints that you do not want to scan (because they are out of scope, they are validated, they need to be scanned separately, etc.).
Note that you don't need to exclude each URL path specifically; you can simply add the common (root) URL path to the excluded URLs.
Tip: You can resize the input box by clicking and dragging on the bottom-right corner.
Attack Options
You can configure the list of Active and Passive tests performed by the Custom Scan individually, via toggle switches. Please see the full list of tests and their description in the sections above:
Available configuration
Note: when scheduling a scan with custom scan options, newly added detectors will not be enabled by default. You must use the Deep Scan option to have all the new features of the scanner in scheduled scans.
Scan options
Tests performed
This is the complete list of tests performed by the Website Vulnerability Scanner with details on how each of them works. These tests run just once, in succession, at the start of the scan process.
Some of the tests are executed during the predefined Light Scan and all of them during the Deep Scan; check the tables below (Initial tests, Active tests and Passive tests) to compare the two scan types. You can also choose which of the tests you want to run by selecting them individually in the Custom Scan.
Initial tests
Test | Description | Light Scan | Deep Scan |
|---|---|---|---|
Fingerprint website | Fingerprinting results in a list of the detected used technologies, tools, third-party software, and their version. This information can serve as a starting point for an attacker, by giving them some directions to further investigate. | ✅ | ✅ |
Server software vulnerabilities | Checks if known vulnerabilities affect the server software. Will output CVEs and a description of each vulnerability. | ✅ | ✅ |
Robots.TXT | Looks for the “robots.txt” file and extract any URLs that are present and in scope for further analysis. | ✅ | ✅ |
JavaScript libraries | Checks if the application uses any outdated JavaScript libraries, which are affected by known vulnerabilities. The output is a list of such detected vulnerabilities. | ❌ | ✅ |
SSL/TLS certificates | The SSL/TLS Certificates test checks if the browser trusts the SSL/TLS Certificate on the server. The most common causes for this error are that the certificate is self-signed, the issuer is untrusted, or it is not valid for the application’s domain. | ✅ | ✅ |
HTTP Debug Methods | This test checks whether HTTP TRACK / TRACE methods are enabled on a web server. | ✅ | ✅ |
Client access policies | Client Access policies are a set of rules in XML files that Adobe Flash and Microsoft Silverlight clients use in the browser. These files specify which parts of the server should be accessible, and to which external domains. We define a vulnerability as allowing any domain to request data from the server, which is identified by a wildcard (a * operator) in certain XML tags in the policy files. This is not necessarily a problem if the website is supposed to be public, but might be a vulnerability if the tested website is supposed to have restricted access. | ✅ | ✅ |
Resource discovery | Resource Discovery searches for common files and directories that represent a possible liability – if exposed – by requesting a list of known common URL paths. Be aware this may increase the overall scan duration. | ❌ | ✅ |
Security.txt file missing | This test checks for the “security.txt” file, usually found at the path /.well-known/security.txt. Please see here for more information on the topic. | ✅ | ✅ |
CORS Misconfiguration | Checks if the website accepts requests from arbitrary origins. If it does, the JavaScript on an attacker-controlled website can make arbitrary requests to the server and read the responses. | ❌ | ✅ |
Active tests
Check for vulnerable parameters that might provide access to sensitive information. The engine crawls the target application, then it sends various inputs into the parameters of the pages and looks for specific web vulnerabilities such as SQL Injection, Cross-Site Scripting, Local File Inclusion, and OS Command Injection.
Test | Description | Light Scan | Full Scan |
|---|---|---|---|
Cross-Site Scripting - XSS | The XSS test tries to detect if the application is vulnerable to Cross-Site Scripting by injecting XSS payloads and analyzing the response. This is one of our more complex tests that uses a real browser to validate that a Javascript payload was triggered. | ❌ | ✅ |
SQL Injections | The SQL Injections test checks for SQL injection vulnerabilities in web applications by crawling, injecting SQL payloads in parameters, and analyzing the responses of the web application. | ❌ | ✅ |
Local file inclusion | Local file inclusion occurs when the web application shows arbitrary files on the current server in response to an input in a parameter. | ❌ | ✅ |
OS command injection | The goal of a command injection attack is to execute of arbitrary commands on the host operating system via a vulnerable application. Command injection attacks are possible when an application passes unsafe user-supplied data (forms, cookies, HTTP headers, etc.) as Operating System commands. | ❌ | ✅ |
Server-Side Request Forgery | Server-Side Request Forgery (SSRF) is a vulnerability that allows a user to force the backend server to make HTTP requests to arbitrary URLs specified in the input parameters. | ❌ | ✅ |
Open Redirect | The backend server incorporates user input into URLs used for redirection. An attacker can use this to redirect users to arbitrary domains. | ❌ | ✅ |
Code Injections (multiple tests) | Code Injection happens when user input is incorporated into a call to a function that interprets and executes code, such as: eval(), setTimeout(), vm.runInContext(). This allows a malicious user to execute arbitrary code on the server. The tests for PHP, Ruby, Perl, Server-Side JavaScript and Python are doing the same thing, but with different payloads tailored for the programming language. These tests use out-of-band detection by making requests to a server controller by us thus resulting in a lot fewer false positives. | ❌ | ✅ |
Broken Authentication | Broken Authentication tests if a page on the target website is accessible both with and without the credentials provided, revealing potential broken access control vulnerabilities. This test runs only if authentication was used on the target as it is required. Please also note that an automated scanner cannot know how sensitive the information on a page is. As a result, this type of vulnerability needs manual validation. | ❌ | ✅ |
Log4j Remote Code Execution | This test is for the popular Log4j vulnerability by triggering requests to a DNS server controlled by us with an ID that was included in the payload. This out-of-band approach is a lot less prone to false positives. | ❌ | ✅ |
Server-Side Template Injection | Server-Side Template Injection happens when user input is directly incorporated into a template and the resulting string is rendered by the templating engine. The impact ranges from XSS, Arbitrary File Read to Remote Code Execution. Currently, we test for template injection in Freemarker, Thymeleaf, Velocity, Smarty, Jinja, and Django. | ❌ | ✅ |
ViewState Remote Code Execution | ViewState is an early attempt by Microsoft to introduce state into HTTP, which is stateless. Microsoft added some security measures to it: a MAC for integrity validation and encryption. When the MAC is disabled, it appears that encryption is disabled as well. If the MAC is disabled, the ViewState will be deserialized automatically. This leads to RCE through deserialization attacks that we test for. | ❌ | ✅ |
Client-Side Prototype Pollution | Prototype Pollution is a vulnerability specific to JavaScript, due to how the language implementation works internally. Being an OOP-capable language, JavaScript has classes and objects. An object's class can be accessed using the “__proto__” keyword. The quirky behavior is that one can overwrite/add attributes to the underlying class blueprint and all future instances will use this new value. This test sends payloads to pollute the base Object via the fragment and query part of an URL and then checks if the base Object has the new attribute. This is all done in a real browser. | ❌ | ✅ |
Passive tests
Passive tests analyze the HTTP responses from the server to find weaknesses in the system.
Test | Description | Light Scan | Deep Scan |
|---|---|---|---|
Security headers | HTTP security headers are a fundamental part of website security. They protect against XSS, code injection, clickjacking, etc. This test checks for the common security headers. | ✅ | ✅ |
Cookies security | Checks the use of :
| ✅ | ✅ |
Directory listing | Directory listings might constitute a vulnerability if it gives access to the server configuration or other sensitive files. | ✅ | ✅ |
Secure communication | Secure communication tests if the communication is done over HTTPS instead of HTTP, which is not encrypted. | ✅ | ✅ |
Weak password submission method | If the communication is done over HTTP, we check if the credentials are submitted using transparent methods like HTTP Basic or Digest Authentication. | ❌ | ✅ |
Commented code / Error codes | Tests if there are suspicious code comments or if the application responds with stack traces or too verbose error messages on certain inputs. | ❌ | ✅ |
Clear text submission of credentials | Tests if the user credentials are sent over HTTP as opposed to HTTPS. | ❌ | ✅ |
Verify domain sources | Checks if the website uses content from 3rd party domains. This isn’t a security vulnerability by itself but might represent one in the case that the outside domain is compromised. We recommend that you keep all the necessary resources on your server and load them from there. | ❌ | ✅ |
Mixed encryption content | Checks if HTML loads over a secure HTTPS connection but other content, such as images, video content, stylesheets, and scripts, continues to load over an insecure HTTP connection. | ❌ | ✅ |
Sensitive Data Crawl | Our scanner engine will analyze the HTTP responses from your target and look for personally identifiable information (PII) like emails, SSN, etcetera. | ❌ | ✅ |
Find login interfaces | Finds login interfaces and returns the HTML code of the forms so a user can use the Password Auditor on it. | ❌ | ✅ |
Authenticated scan
You can run both an unauthenticated and authenticated scan on the target website. When authentication is set as disabled, (available for the Deep and Custom scan types) the web scanner focuses its assessment on a limited subset of application functionality, specifically the elements accessible before user authentication. Of course, certain vulnerabilities within the application such as a broken authentication mechanism can only be detected once logged in.
Conducting authenticated scans offers several advantages. Firstly, it allows for simulating activities carried out by a malicious user with authenticated access, thereby encompassing additional attack vectors. Authenticated users typically have broader access to application functionality compared to unauthenticated users. By performing authenticated scans, the assessment team can provide a more comprehensive analysis of the security posture, ensuring a thorough identification of potential vulnerabilities.
Authentication methods
The Website Scanner supports four types of authentication methods: Recorded (authentication based on a predefined recording), Automatic (a form-based authentication), Cookies (authentication through cookies), and Headers (authentication through headers).
Note: the “Check Authentication” button validates the authentication without initiating the scanning process. It will provide a screenshot from the browser, cropped at 1280x720px, indicating whether the authentication was successful or not.
1. Recorded (recording-based authentication)
To be able to authenticate on a specific target, automated scanners need to fulfil the requirements of loading dynamic pages and components which are necessary for complex web applications. The Recorded authentication method uses Selenium technology to capture user events during the login process for the scanning account. Users are required to upload the recorded authentication process, following the steps outlined below, to obtain the necessary information.
The process is demonstrated on video and detailed in a dedicated Support article.
2. Automatic (form-based authentication)
With this option, the authentication is achieved through a valid pair of credentials in the target application. This method involves identifying the login form in the URL provided by the user, sending the credentials, and capturing a screenshot of the response.
While easy to configure, it cannot cover complex login cases, involving more than one page, more than two credential fields or other login procedures that require further user interaction. For those cases, please use one of the other authentication methods.
If selected, you will need to provide: the URL of the interface on which the authentication takes place, the username of the account to be used and its subsequent password.
For more information on how to set up the Automatic authentication method as well as basic troubleshooting, please check our dedicated support article.
3. Cookies (cookie-based authentication)
This authentication option emulates the behavior of a web browser that possesses an existing session cookie. Users are required to input a valid session cookie in the 'Cookie header' field. This session cookie must be extracted from a previously established web session (manually log into your web application and retrieve the cookies from your browser).
➥ Info: Web browsers receive HTTP Cookies from the server, which are data pieces commonly used to identify a user's web session (also known as session cookies). Upon receiving a session cookie, the browser includes it in each HTTP request made to the server, ensuring association with the specific user.
With this authentication method, the spidering (the systematic exploring and mapping of the target website structure and content) and active scanning start directly. If the cookie is correct, the scan will result in more URLs discovered and analyzed for vulnerabilities.
If you need help obtaining a cookie from your browser, please see this short tutorial: How to get the session cookie?
Note: the provided cookie will be used for every request. The scanner is unable to check the validity of the provided cookie; it will utilize the cookie “as is”, and it becomes your responsibility to validate whether the scan has successfully accessed the desired sections of the application.
For more information on how to set up the Cookie authentication method as well as basic troubleshooting, please check our dedicated support article.
4. Headers (headers authentication)
This authentication method uses HTTP headers. Those facilitate communication between a client and a server, transmitting information about the client browser, server, accessed page, and other relevant details. Certain applications use specific headers to establish user sessions, (login sessions).
The Cookie-based method utilizes cookies, which are a distinct type of headers. However, not all applications rely on cookies for user authentication. Some applications depend on other special headers, such as token-based authentication (JSON web token), to provide an additional layer of security. Consequently, users who need to scan these types of websites or applications require the Headers Authentication Method for authentication.
Note: the “Check Authentication” button is not yet implemented for the Headers method. The authentication check is automatically made during the scan process itself.
For more information on how to set up the Headers authentication method as well as basic troubleshooting, please check our dedicated support article.
Parameter quick reference
Target | Enter the website URL to scan. Note that the scanner will follow redirects on the same domain by default. If you want to modify the redirects policy, see the “Follow Redirects” option. |
|---|---|
Get a quick and brief overview of the website. | |
Default scan option. This has all the tests/options enabled by default, except for the Resource Discovery. It can run up to 24 hours and will search for OWASP Top 10 vulnerabilities. | |
Customized scan routine that allows you to set the specific checks you want to run or scan for only a type of vulnerability. You can also limit the number of requests per second/depth of the scan, exclude critical URLs and many other parameters of the scan. | |
Custom Scan - Initial Tests | Available only for the Custom Scan type. Allows you to define which of the Initial Tests you would like to be performed in your Custom Scan. |
Custom Scan - Engine Options | Available only for the Custom Scan type. Define the engine options for your custom Scan:
|
Custom Scan - Attack Options | Available only for the Custom Scan type. Allows you to define which of the Attack options (Active and Passive checks) you would like to be performed in your Custom Scan. |
Authentication | Available only for the Deep and Custom Scan types. Allows you to enable the authenticated scan method. If disabled, the web scanner will only cover the application functionalities that are accessible prior to user authentication. |
Authentication - Recorded | Available only for the Deep and Custom scan types.
|
Authentication - Automatic | Available only for the Deep and Custom scan types. Use regular authentication (username/password combination). Provide the URL, username, and password parameters. |
Authentication - Cookies | Available only for the Deep and Custom scan types. Use cookies from an already authenticated session. Paste the cookie(s) into the “Cookie header” field. The scanner will send them to the server, behaving like a regular authenticated client. |
Authentication - Headers | Available only for the Deep and Custom scan types. Use HTTP custom headers for authentication (JWT tokens, Authorization headers, etc.). Paste your authentication header in the “HTTP Headers” field. Authorization: Bearer [your token] |
Define the maximum runtime allowed for the scanner (in minutes). The default is set to 1440 minutes (24 hours). A minimum runtime of 5 minutes can be configured when quick results are desired. | |
Follow redirects - Never | Select this option to prevent the scanner from following any URL redirects. |
Follow redirects - Same-host only | Set the scanner to follow the HTTP redirects that point to the same hostname only. The following types of redirects will be followed:
|
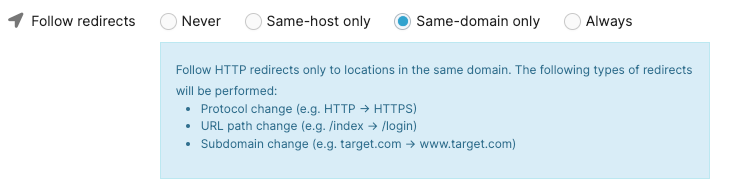
Follow redirects - Same-domain only | Set the scanner to follow the HTTP redirects that point to the same domain only (default option). The following types of redirects will be followed:
|
Follow redirects - Always | The scan will follow the HTTP redirects to any location, even to a different domain. |
Allows you to set how to receive notifications about the scan. | |
Notifications - Workspace | Allows you to get notifications when the scan results match the trigger conditions (see “Settings” → “Notifications”). |
Notifications - Custom | Allows you to set Custom notification triggers according to scan-specific parameters:
See the section below for parameter details. Note that this setting overrides the workspace notification setting (“Settings” → “Notifications”). |
Notifications - None | Scan notifications are disabled. |
Schedule Scan | Define a time for your scan to run by selecting it from the drop-down list next to the "Start Scan" button (which is the default action set). The configurable parameters include "Start on", "Time zone", and "Repeat every" (which enables you to set a scanning recurrence). You can use this option alongside the "Custom scan time" and "Notifications" options mentioned above. Note: if you schedule more scans than the available slots allowed by your current subscription plan (Basic - up to two parallel scans, Advanced - up to five, and Teams/Enterprise - up to ten), the excess scans will be placed in a waiting queue. They will be initiated in the order they were scheduled, as soon as a new scan slot becomes available. |
Custom notification triggers
You can define granular trigger conditions for notifications to be sent - according to scan status and whether a technology or vulnerability is found, and subsequently define what actions to perform when those triggers are fired.
Technology Found
Define technology name tags that will determine this trigger to fire. The tags support alphanumeric characters (no spaces). The trigger will fire when any of the elements in the list are detected.
Vulnerability
This type of trigger will fire when a certain type of vulnerability is detected. There are three types of vulnerability triggers:
Risk Level - fires when a selected risk level is detected; these correspond to the Risk Levels from the Report (Info, Low, Medium, High).
Finding name - fires when a specific Vulnerability name is or contains the defined string.
Confirmed tag - fires when a “Confirmed” tag is detected; see the “Validating the findings” section, below.
Note that you can add two or all three of the conditions above to the trigger; in this case, it will fire only if all the conditions are met.
Scan status
Choose this trigger when you want to be notified when a specific Scan status is reached. Available statuses are:
Timed out
Stopped by the user
Finished
VPN Connection error (if a VPN is used to access the target)
Authentication error (if the Authenticated scan is used)
Connection error (the connection to the target is lost)
Aborted
Failed to start
Note that you can use any combination of the statuses above; in this case, the trigger will fire only if all the conditions are met.
Notification actions
Set the where to send the notification if the defined trigger is fired:
Send to default email (defined in your profile)
Send to additional emails (press enter/return between addresses)
Send to Webhook (requires Webhooks to be defined under Integrations > Webhooks)
Send to Slack channel (requires Slack integration to be defined under Integrations > Slack)
Understanding the report
All findings detected by the vulnerability scanners undergo a classification process, with each of them being assigned to a specific Risk Level. This categorization is determined by the severity level of each vulnerability, taking into account factors such as the Common Vulnerability Scoring System (CVSS) score, (more information here) the default settings of the scan engine, as well as our internal framework logic.
Risk levels
🟢 [Informational] - Findings that hold no inherent severity and can be addressed at your discretion. They can also be optionally excluded from the final report, based on your preferences.
🔵 [Low] (CVSS score <4) - Vulnerabilities classified as low-risk typically pose a minimal impact on the organization's business operations. These vulnerabilities usually increase the damage potential to a business when exploited alongside a high-risk vulnerability.
🟠 [Medium] (CVSS score >=4) - For successful exploitation, intruders need to actively manipulate individual targets when dealing with medium-risk vulnerabilities. While these vulnerabilities should not be disregarded, they demand a certain level of effort to be fully utilized in a real attack.
🔴 [High] (CVSS score >=7.5) - High-risk findings represent vulnerabilities that are susceptible to relatively straightforward exploitation by potential intruders. Exploiting high-risk vulnerabilities carries the potential for substantial downtime and/or significant data loss. It is crucial to prioritize addressing these vulnerabilities promptly.
Status types
The “Status” column in the findings report allows for effective monitoring of remediation or selective exclusion of specific findings from reporting purposes.
To modify the status of each of the findings, use the "Modify Finding" button located in the upper menu.
Open - This status denotes the default state assigned to newly identified findings by our scanning tools.
Fixed - Upon implementing remediation measures, findings can be modified to this status. However, if a previously fixed finding reappears in subsequent scans, it suggests potential inaccuracies in the applied remediation measures, warranting a thorough verification.
Accepted - Findings can be designated as "Accepted" to indicate that certain issues will not be remediated. By marking vulnerabilities as accepted, they can be effortlessly excluded from reports with a single action.
Ignored - Findings labelled as "Ignored" are automatically omitted from reports. This preference is retained for subsequent scans performed on the same target.
False Positive - If there is reason to believe that a finding is wrongly reported, it could potentially be classified as a false positive. You have the option to navigate to designate a specific finding as either "False Positive". Just like for the “Ignored” status, this action ensures the automatic exclusion of the finding from the scan results.
Note: we strongly advise validating the findings (see below) in the report manually before marking them as “Ignored” or “False Positives”.
Validating the findings
It is strongly advised to review all reported vulnerabilities and perform manual verification of each identified issue.
Our scanners employ automated validation techniques by exploiting identified vulnerabilities and presenting users with proof of exploitation in order to facilitate the validation process. These validated findings are pre-tagged as "CONFIRMED."
However, some findings cannot be automatically validated and will be automatically categorized as "UNCONFIRMED". This implies that these findings may or may not be legitimate, as false positives are an inherent risk associated with automated scanning tools.
For simplified manual validation, some findings offer an easily accessible exploit that executes the attack vector directly from the scan result. Use the "Replay Attack" button to assess the results of the exploit.
Once a finding has been verified, users can navigate to the findings tab, select the relevant finding(s), access the "Modify Finding" function, and choose the "Change Verified" option.
Note: validating "UNCONFIRMED" findings falls outside the scope of our support service. Such requests can be accommodated as an additional activity through our managed services team.
FAQ’s
When should I perform a web application security scan?
Performing a web application security scan is necessary at various stages to continuously enhance the cybersecurity posture of websites and web applications.
In addition, milestones that trigger the need for a website security check include launches, website and web app architecture overhauls, changes in the technology stack and functionality, as well as whenever critical vulnerabilities emerge that affect your web apps.
Regular checks for security vulnerabilities help prevent several setbacks, such as:
Preventing search engine blacklisting due to malicious code injection.
Avoiding website hijacking that negatively impacts the reputation of website owners.
Ensuring compliance with standards like PCI DSS, SOC II, HIPAA, GDPR, ISO, the NIS Directive.
Minimizing the risk of the website being exploited by malicious hackers for phishing attacks or distributing malware, among other potential threats.
Why does the scan take such a long time?
When you use the Light Scan version, the completion time is typically under 2 minutes.
Most website scans which use the Deep Scan version finish in under 1 hour, but can last for up to 24 hours, depending on how elaborate the web app is.
The duration of a scan varies greatly depending on the scan settings, the Spidering depth, the number of tests, etc., and ranges from a few minutes to several hours. While it runs, the scan can appear stagnant or unresponsive. To ascertain the current status, users can simply click on the target name, which will display a progress bar information tooltip, revealing the ongoing test being conducted.
If, however, the scan time exceeds the 24-hour mark, please contact our Support team at support@pentest-tools.com.
Why does the Website Scanner seem to get stuck at 47%?
Sometimes the Website Scanner may remain for a while at 42% or 47% but it’s not stuck. We recommend you let the scanner open even if you see it stagnate.
Since the scanner can make a considerable number of requests to the target server, the whole scan could take up to several hours.
Why can’t I perform an authenticated website scan or why does the authentication process fail?
There can be multiple causes for a failed authentication. The most common causes include:
The fact that the credentials are incorrect
Your website has a CAPTCHA code on the login
The target application has two- or multi-factor authentication
If using the cookie authentication method, the cookie size is larger than 5000 characters
These scenarios and more, as well as their respective solutions, are detailed in a dedicated Support article.
Why am I receiving errors during the scan and what measures should I take?
There are different approaches depending on the type of error you encounter.
Connection errors (or “Conn error”) can have various causes:
Our server's requests are being blocked by a firewall or WAF.
An authorization issue prevents the target from responding to our HTTP requests.
Geo-blocking situations where the target refuses requests from specific regions. Please note that our servers are located in the UK.
To address these issues, it is recommended to whitelist our scanner's IPs or FQDN.
A "Timed out" error means that the scan has reached the built-in scan time limit of 24 hours (or your custom-defined scan time).
The most likely cause is a slow-responding server or the server completely stopping its response during the scan process. To work around this issue, you can decrease the requests per second by modifying the appropriate parameter with a Custom Website Scan and/or disabling the Resource discovery test.
The scan “Failed to start”
This error indicates an issue encountered while initiating the scan at that particular time. We suggest retrying the scan after a few minutes.
“Target URL redirects to another URL that might be out of scope”
We recommend adjusting the Follow Redirects parameter to: Never.
Why am I receiving unexpected results such as false positives or false negatives?
While we make every effort to provide the most accurate results possible, there may be instances where a finding might go unnoticed. In such cases, you have the option to actively report the issue to us for further investigation.
Will the scanning overload our servers?
The functioning of the web server may be impeded depending on the amount of traffic it handles, as our scanners can generate up to 100,000 HTTP requests. The requests per second range from 100 per second (which is the default for scans initiated from the authenticated platform) to 10,000 requests per second for scans initiated through our API.
Therefore, we recommend conducting scans during non-business hours whenever feasible. The limit value for the number of requests per second can also be adjusted as needed by choosing a Custom Website Scan.
For further information, FAQ’s and articles about how to use and run the Website Vulnerability Scanner, please check our Support platform.